怎样计算相似用户

在推荐系统中,item(结合我们的业务,后面都用文章代替)的召回是个很重要的部分,单一类别的召回往往很难把用户的所有需求都涵盖,很多时候我们要从多种维度进行召回,比如兴趣标签、用户的人口学信息等等。由于用户属性的稀疏性,真正命中的召回类别并不是很多,所以召回的种类越多,那么其中包含用户感兴趣的内容就越多。
相似用户召回就是从用户相似性这个维度来召回文章,所谓相似用户就是和当前用户口味相近的用户,我们可以把这些用户爱看的内容推荐给当前用户。从目前上线结果来看,这个召回的效果是最好的。
我们想要计算相似用户,那就产生了四个问题:
- 使用什么数据
- 如何处理数据
- 如何定义用户口味
- 如何计算相似
使用什么数据
由于我们想要计算用户的新闻口味,那我们需要的就是用户的行为数据,虽然这份数据在不同业务上有不同的内涵,但是核心都是一样的,即下面的四元组:
<UserID,ItemID,Action,Time>
它表示某个 用户 在某个 时间 对某个 内容 进行了某个 操作 ,在我们的业务场景下,主要关注的还是用户对文章是否产生了点击行为。
如何处理数据
有了原始数据,我们该如何处理行为数据呢?一个经典的方法是把行为数据看作一个矩阵,然后做矩阵分解映射到一个低维度空间上,这样的好处是用户和文章都处于一个相同的维度,不但用户-用户,文章-文章之间可以计算相似度,而且用户-文章之间也能计算相似度。这是最古老也是最有效的协同过滤方法。但是我们没有采用这个方法,原因如下:
- 用户的行为是隐式反馈(点或没点),存在较大的随机性,即单凭一次行为不能判定用户是否感兴趣。
- 数据的共现可能存在误差,不能反映数据之间的关联,比如有的用户喜欢娱乐新闻,那么他很有可能把娱乐频道下的文章都看了一遍,那这样学习出来的模型并不能体现协同过滤的发现多样性的优点。
关于隐式反馈的协同过滤,有些经典的paper做了详细的分析和介绍,感兴趣可以去找找,比如:collaborative filtering for implicit feedback datasets等
实际上我们并没有直接用文章id,而是使用文章对应的文本特征,比如tag、topic和关键字等信息,首先,把用户对文章的行为转换为用户对相应文本特征的行为,并且汇总,那数据就变成:
<UserID, ‘娱乐’, Action, Count>
<UserID, ‘财经’, Action, Count>
Count是行为发生的次数,因为它对文本特征进行了汇总,所以得到的数据集要比之前的更稠密些。
下面要做的就是对这份数据(或者说是信号)进行处理,换句话说这个Action在你的业务中如何解释,有什么含义。具体业务的不同,处理方法也不同,在我们这里,Action主要是点或未点,因此我们可以获得一个点击率,那这份数据的物理意义也就是 用户对文本特征的历史点击率 。
这里有两个地方需要特别注意:
- 当用户行为稀疏时,如何处理信号?
- 如何去掉当时的背景?比如出现爆炸新闻时,所有人都会去看,但是不代表用户对此感兴趣。
对于1,可以赋予数据一个合理的先验,然后根据信号计算后验,如何获得先验,就要从数据中统计了。对于第2点,可以统计一下那段时间的标签热度,对热门的标签进行降权。
关于如何衡量用户兴趣,不是简单一两句就能说清楚的,以后可以单独写篇文章介绍下。
如何定义用户口味
现在我们有了用户对文本特征的历史统计,那如何衡量用户的口味呢?一种做法是直接使用这些统计项,把它作为特征,比如把点击率作为用户兴趣的衡量,这不是不可以,最早我们就是这么干的,但是它的效果并不好,主要是因为单个用户的行为稀疏性,很难真正反映用户的真实兴趣。
我们的做法借鉴了文本相关的思路,具体来说就是LDA,在Topic Model中,文档被看作是Topic的分布,而Topic看作是词的分布,通过LDA training,就可以获得一个Topic模型,每篇新文章都可以映射到这个Topic分布上。
在相似用户的问题上,我们可以转换一下思路,把用户看作是Topic Model中的文档,而他的历史统计则是文档中的词,那用户就是一组Topic的分布,而Topic就是一组文本特征的分布,这里的Topic就是我们所求的口味或者兴趣。
现在我们的问题对标到一个成熟的模型上了,下面的工作就是训练出一个Topic Model,这一步我就不详细介绍了,方法太多了。但需要说明一点,我们的历史统计值是个小数,而LDA里面需要一个整数(一般表示词频),所以我们做了一个转换,把小数映射到整数范围,保证可以正常工作,这个转换函数根据不同业务有不同的定义,需要观察数据进行调参。
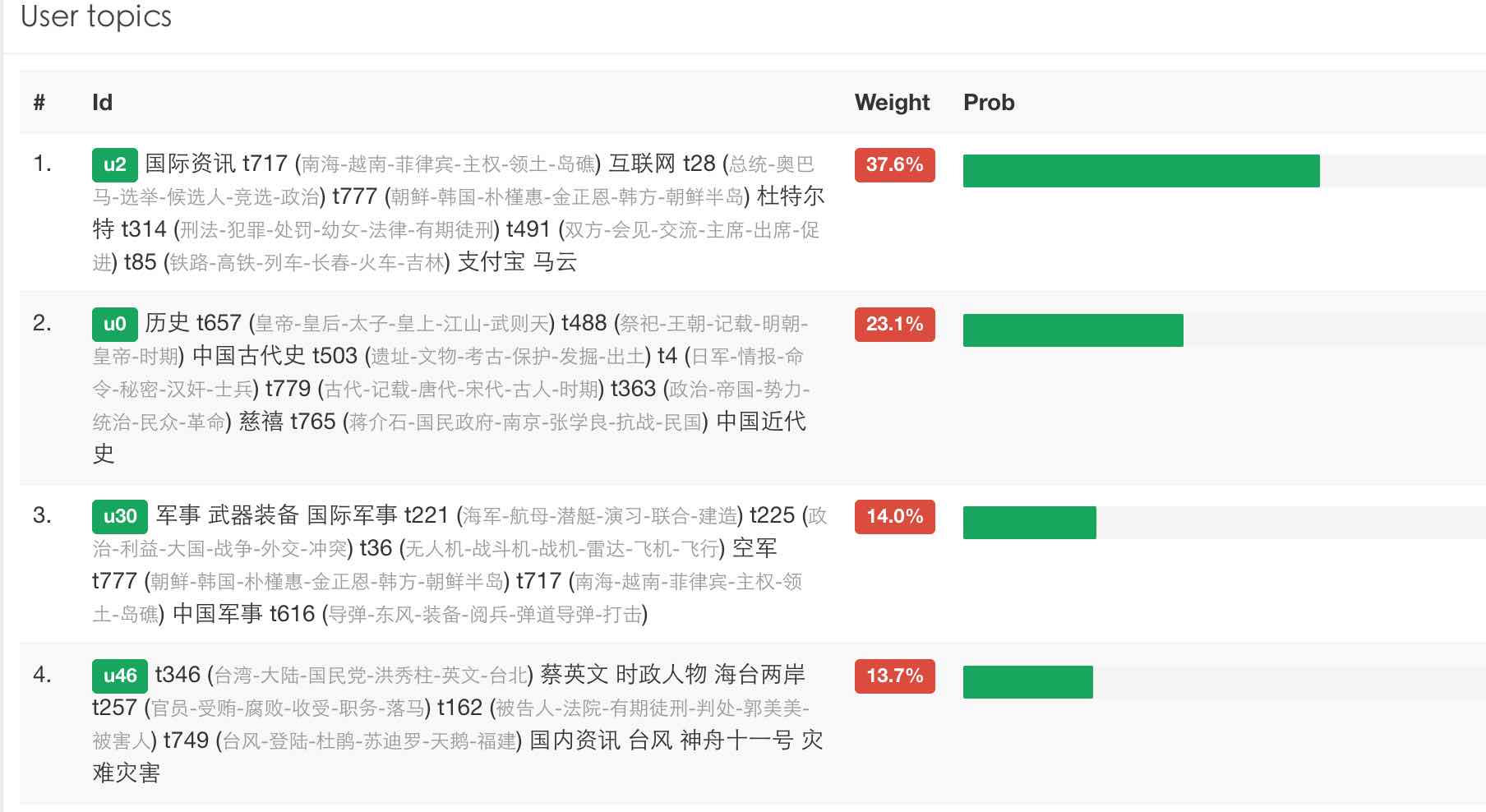
如何计算相似
现在我们终于把用户的兴趣识别出来了,对于每个用户,我们都可以根据他的历史统计,获得兴趣分布,并保存下来。这样所有用户都映射到一个相同的维度上,就可以计算他们之间的相似度了,选定一个距离函数,来计算两两用户之间的相似度,找出最近的用户即可。
总结
这种方法基于行为来分析用户的口味,然后找出口味相似的用户,本质上也是协同过滤。除了计算相似用户,它还有其他的用法,比如把某类用户(兴趣分布大于某一阈值的用户)都爱看的文章聚合起来,作为该类用户的召回,就是一个很不错的思路。
参考
- Measuring Personalization of Web Search
- It is not just what we say, but how we say them- LDA-based behavior-topic model
- Analyzing User Modeling on Twitter for Personalized News Recommendations
- An Exploration of Improving Collaborative Recommender Systems via User-Item Subgroups
blog comments powered by Disqus